- Published on
Normalization(정규화) 개념 정리
- Authors

- Name
- Eunsu Kim
- @eunsukimme
많은 ML 알고리즘들은 데이터의 각 feature들을 비교하여 데이터의 트렌드를 찾고자합니다. 그런데 만약 feature들의 스케일이 각각 상이하면 문제가 될 수 있습니다.
예를 들어, 집 데이터셋을 생각해 봅시다. 두 가지 feature로 방의 개수, 집의 나이(연도 수)를 고려해볼 수 있습니다. 그러나, 방의 수 보다 집의 나이가 더 큰 스케일을 갖고 있어서 다른 feature를 dominate할 수 있습니다. 아래의 그래프를 봅시다.
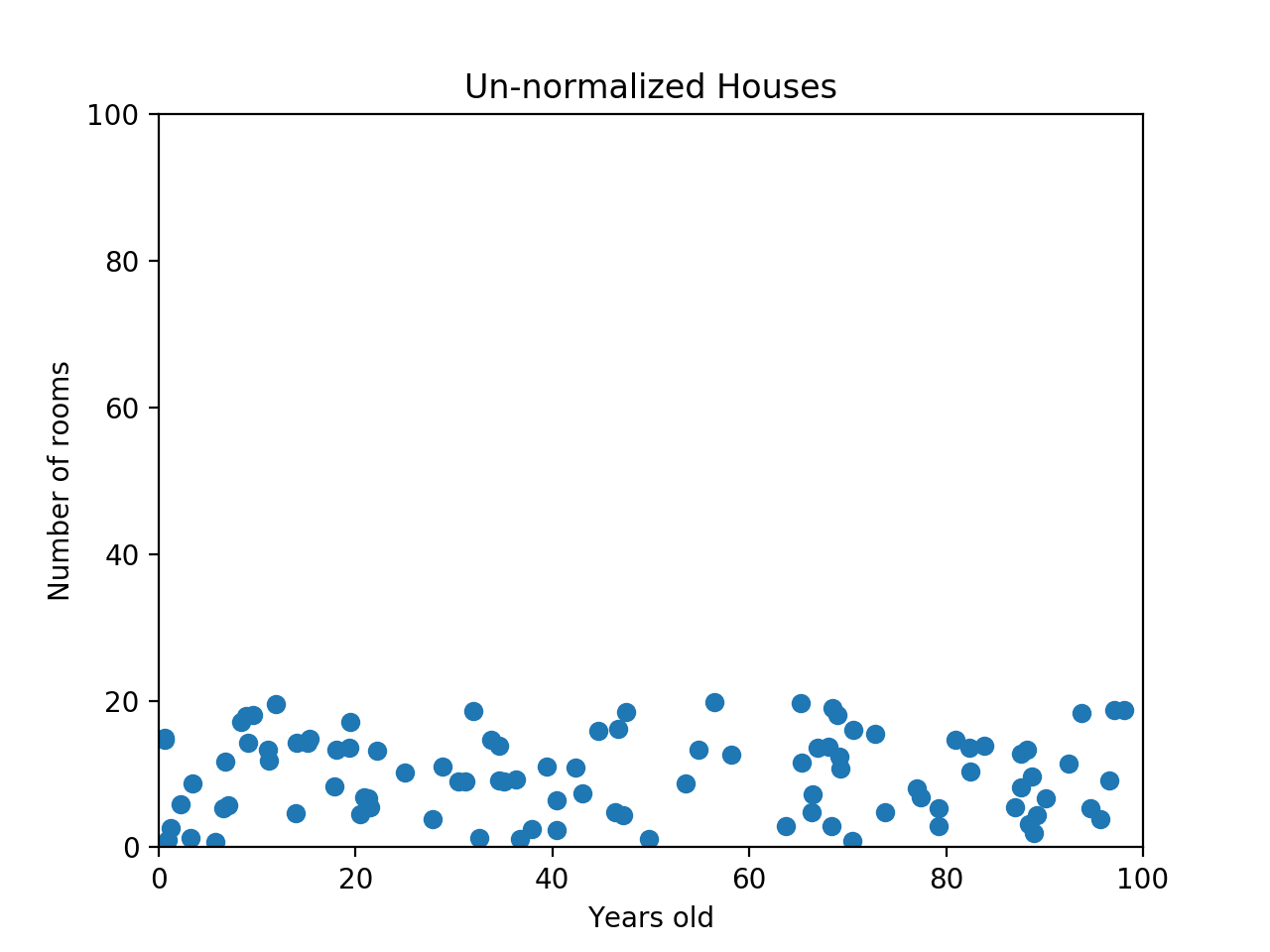
데이터가 찌그러져 보이는 것이 문제가 있음을 암시합니다. ML 알고리즘이 방의 수 2와 20은 큰 차이가 있도록 받아들여야 하는데 현재 데이터로는 두 집의 나이가 100까지 차이날 수 있기 때문에 방의 수의 차이가 그렇게 영향을 미치지 못 합니다.
더 극단적인 예를 들어보자면 x축이 집의 나이가 아니라 집값이 될 수 있습니다. 그렇게 된다면 데이터는 더 찌그러져 보일 것이고, 방의 수는 몇 천만이 차이나는 집값에 비해 훨씬 ML 알고리즘에 덜 영향을 미치게 될 것입니다.
Normalization(정규화)의 목적은 바로 여기에 있습니다. 모든 데이터들의 스케일을 동일하게 만들어 각 feature들이 동등한 중요도를 갖도록 하는 것입니다. 아래의 그래프는 위 그래프에 min-max normalization을 적용한 것입니다.
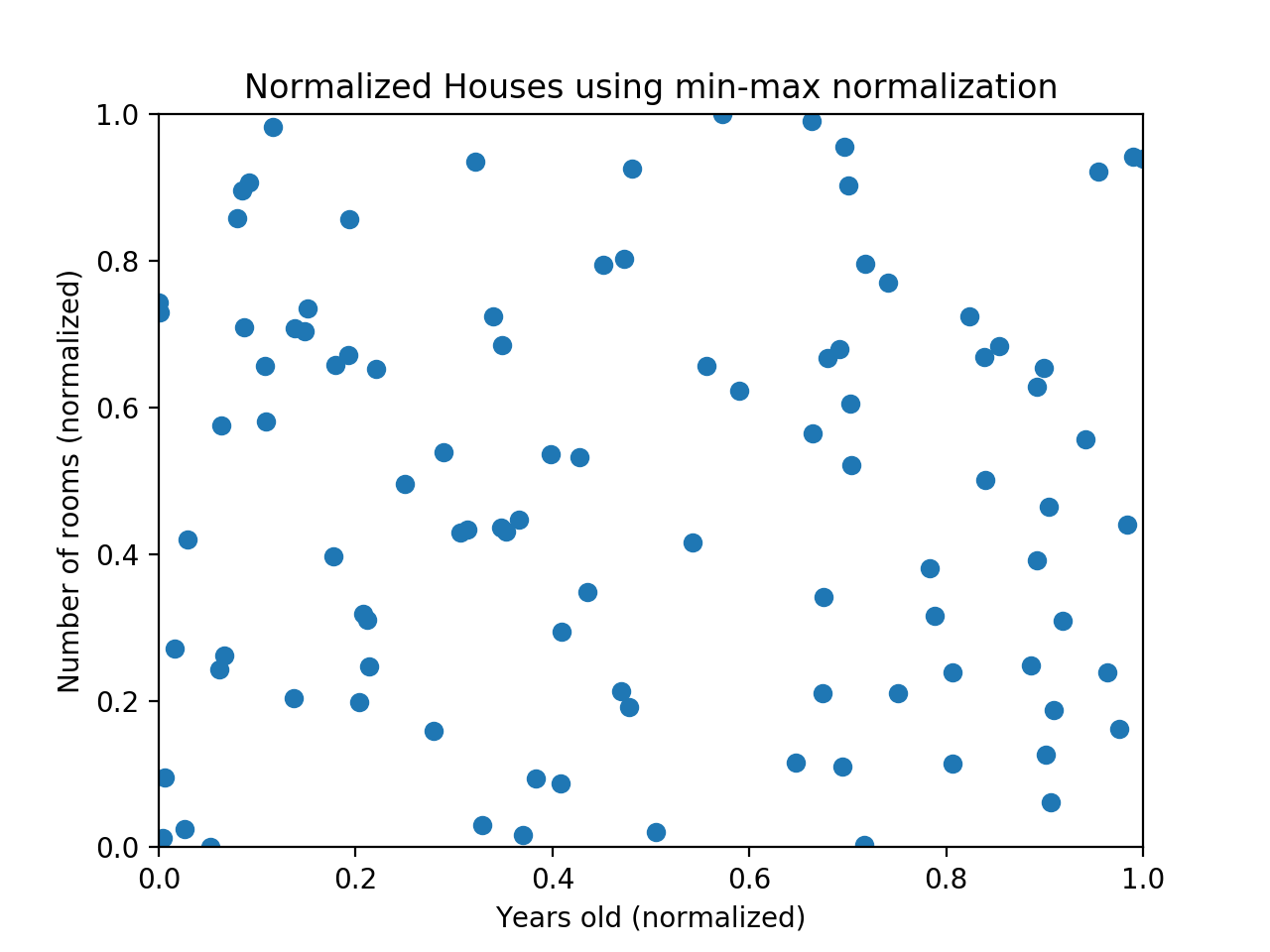
Min-Max Normalization
Min-max normalization은 데이터를 정규화하는 방법 중 가장 흔한 방법입니다. 모든 feature에 대해, 각 feature의 최소값을 0으로, 최대값을 1로 변환하고 그 사이의 값들을 0과 1사이로 만듭니다.
예를 들어, 한 feature의 최소값이 20이고, 최대값이 40이면 30이라는 값은 0.5로 변환됩니다. 이를 계산하는 공식은 다음과 같습니다.
Min-max normalization은 한 가지 중요한 단점을 가지고 있습니다. 바로 outliers(이상치)를 제대로 다루지 못 한다는 것입니다. 예를 들어, 0과 40사이의 99개의 값이 있고 100인 값이 하나가 있는 데이터에 min-max normalization을 적용하면 99개의 값들이 0과 0.4 사이로 변환됩니다. 데이터는 여전히 찌그러져 보이게 됩니다. 아래의 그래프를 봅시다.
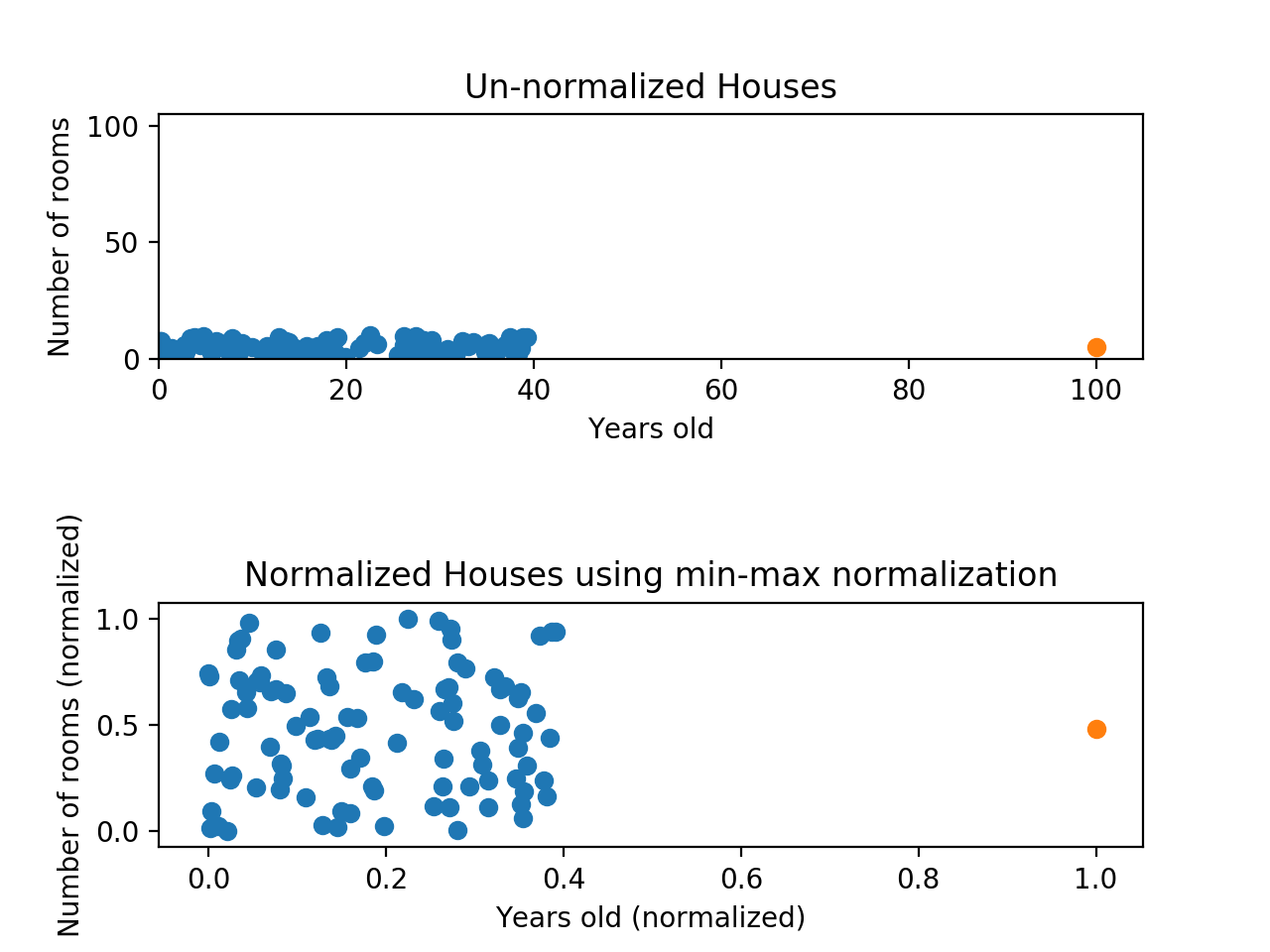
정규화로 인해 y축으로는 문제가 잘 해결되었지만, x축으로는 여전히 문제가 존재합니다. y축의 값은 0부터 1까지 다양하지만, x축 값은 차이가 0부터 0.4까지 뿐입니다. 결국 위 데이터는 정규화 하였음에도 불구하고 y축 feature가 x축 feature보다 더 dominate할 것입니다.
Z-score Normalization
Z-score normalization은 위와 같은 이상치로 인한 issue를 피하기 위한 정규화입니다. Z-score normalization 공식은 다음과 같습니다.
여기서 µ는 feature의 평균값을 의미하고 σ는 feature의 표준편차를 의미합니다. value가 평균에 가깝고 표준편차가 클 수록 0에 가까워집니다. MIn-max normalization을 적용했던 데이터에 대해 이번에는 z-score normalization을 적용해 봅시다.
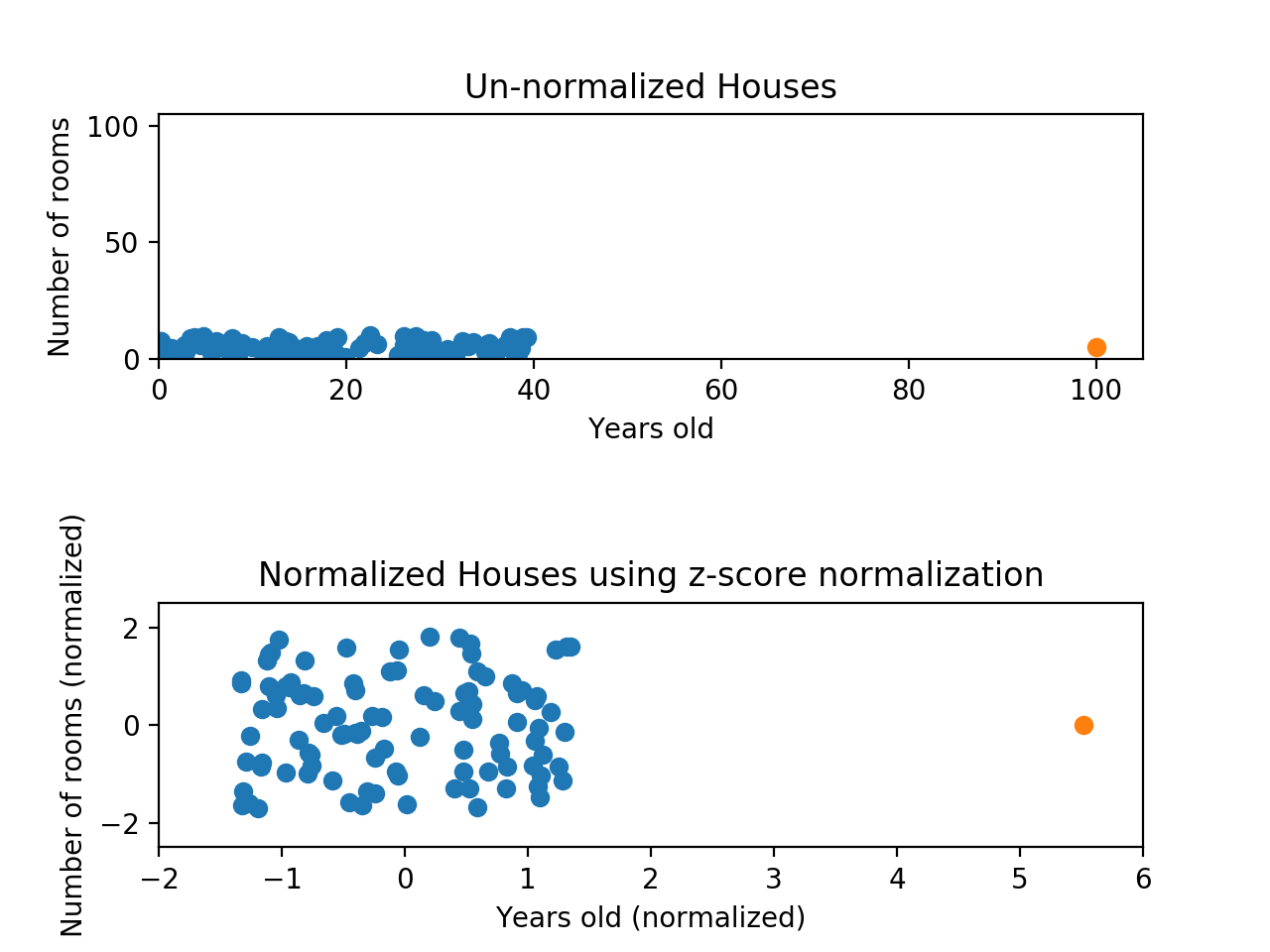
데이터가 여전히 찌그러져 보이지만, 자세히 들여다 보면 데이터가 거의 비슷한 스케일로 나타나는 것을 확인할 수 있습니다. x축과 y축에서 이상치를 제외한 데이터 모두 -2와 2사이에 분포한 것을 알 수 있습니다. 한 가지 단점은 완전히 동일한 스케일을 갖지 않는다는 것입니다.
Min-max normalization의 경우 각 feature의 값들이 항상 0과 1사이라는 것을 보장해 주었습니다. Z-score normalization의 경우, x축은 -1.5부터 1.5까지에 대부분의 데이터가 분포한 반면 y축은 -2부터 2까지에 데이터가 분포하고 있습니다. 분명한 것은 한 가지 feature가 다른 것들을 dominate하지 않도록 한다는 것입니다. 이는 확실히 이전의 min-max normalization보다 더 좋은 것 같습니다.
Review
이번 포스팅에서는 normalization(정규화)에 대해서 간략히 살펴보았습니다. 정규화는 한 가지 feature가 다른 것들은 dominate하지 않도록 해주는 매우 중요한 역할을 해줍니다. 이번 포스팅에서 살펴본 두 가지 정규화는 다음과 같습니다.
- Min-max normalization: Guarantees all features will have the exact same scale but does not handle outliers well.
- Z-score normalization: Handles outliers, but does not produce normalized data with the exact same scale.