- Published on
Matplotlib로 Bar(막대), Pie(원), Histogram(히스토그램) 그리는 방법
- Authors

- Name
- Eunsu Kim
- @eunsukimme
이번 포스팅에서는 Matplotlib를 활용하여 선 그래프 뿐만 아니라 다양한 형태의 그래프를 그려보도록 하겠습니다. 또한, 데이터를 시각화할때 어떤 그래프로 나타내야 하는지도 함께 알아보도록 하겠습니다.
Bar Chart
Matplotlib는 bar chart(막대 그래프)를 그릴 수 있도록 plt.bar() 메서드를 제공합니다. Bar chart는 여러 카테고리의 데이터를 비교할 때 유용하게 사용할 수 있습니다. Bar chart로 표현할 수 있는 몇 가지 데이터는 다음과 같습니다.
- x 축 — 유명한 건물들, y 축 — 건물의 높이
- x 축 — 다양한 행성들, y-axis — 각 행성의 공전 주기
- x 축 — 프로그래밍 언어들, y-axis — 각 언어로 쓰여진 동일한 기능을 하는 함수의 코드 길이
plt.bar() 메서드는 다음 두 가지 파라미터를 받습니다.
x-values— 각 막대 그래프의 x 축 값들y-values— 각 막대 그래프의 높이
대부분의 경우 x-values는 [0, 1, 2, 3, ...] 형태와 유사하며 y-value 와 같은 길이입니다. 간단한 bar chart를 다음과 같이 그릴 수 있습니다.
days_in_year = [88, 225, 365, 687, 4333, 10756, 30687, 60190, 90553]
plt.bar(range(len(days_in_year)), days_in_year)
plt.show()
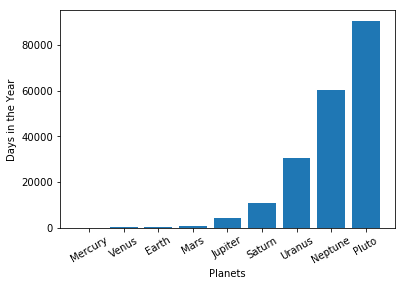
위 경우 x 축 값들이 숫자로 구성되있어서 그래프를 이해하기가 어렵습니다. 이 때 x 축의 ticks를 다음과 같이 변경할 수 있습니다. 한 가지 주의해야 할 것은, x-labels를 설정하기 전에 반드시 x-ticks를 설정해야 합니다. 왜냐하면 디폴트 ticks는 하나의 막대에 하나의 tick이 할당되는것을 보장해주지 않기 때문에 label이 잘 못 위치할 수 있기 때문입니다.
ax = plt.subplot()
ax.set_xticks([0, 1, 2, 3, 4, 5, 6, 7, 8])
ax.set_xticklabels(['Mercury', 'Venus', 'Earth', 'Mars', 'Jupiter', 'Saturn', 'Uranus', 'Neptune', 'Pluto'], rotation=30)
plt.xlabel('Planets')
plt.ylabel('Days in the Year')
plt.show()
Side-By-Side Bars
Bar chart는 같은 axis를 공유하는 여러 set의 데이터를 시각화하는데도 유용합니다. 아래 그림은 미국과 중국의 인구 수 추이를 side-by-side 막대 그래프로 나타냅니다.
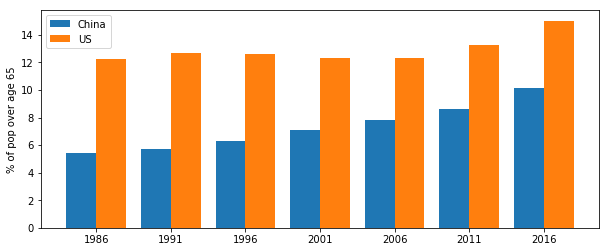
위 그림은 총 7 set의 막대가 있고, 각 set에는 2개의 막대가 존재하고 있습니다. 각 막대의 width는 0.8 로, 이는 Matplotlib에서 제공하는 막대의 디폴트 값입니다. 위와 같이 두 개의 막대를 동시에 그리기 위해선 각 막대에 대한 위치를 간단한 로직으로 계산해주면 됩니다. 먼저, 파란색 막대의 위치를 계산해봅시다.
# 파란 막대의 x 위치를 계산합니다
n = 1 # 한 set에서 나타나는 데이터의 순서 (첫 번째 이므로 1)
t = 2 # 한 set에 포함되는 데이터의 수
d = 7 # 총 set 수
w = 0.8 # 막대의 width
x_values1 = [t * element + w * n for element in range(d)]
같은 방법으로, n 을 2로 변경하고 주황색 막대의 위치를 계산해줍니다.
# 주황 막대의 x 위치를 계산합니다
# t, d, w 값은 위에서 계산한 값과 동일합니다
n = 2 # 한 set에서 나타나는 데이터의 순서 (두 번째 이므로 2)
x_values2 = [t * element + w * n for element in range(d)]
Side-by-side 막대 그래프를 그릴 때 마지막 list comprehension은 변경 할 필요가 없습니다. 단지 n, t, d, 그리고 w 값만 바꾸어주면 됩니다.
Stacked Bars
만약 두 데이터를 비교하면서 동시에 총합에 대한 정보를 얻고자 한다면 막대 그래프를 나란히 배치하는 대신 수직으로 쌓을 수도 있습니다. 예를 들어 일주일간 공부와 게임에 할애한 시간을 비교하고 총 할애한 시간에 대한 정보를 얻고자 한다면 다음과 같은 stacked bars 를 그릴 수 있습니다.
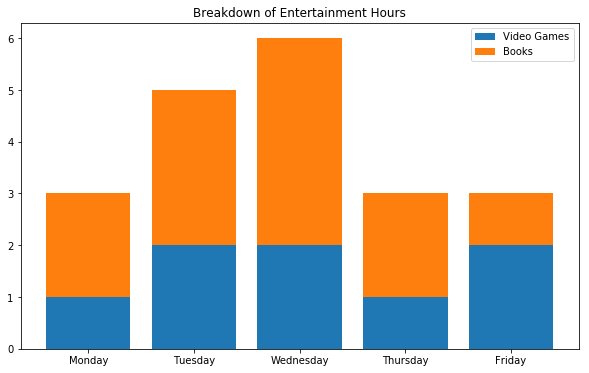
이는 아래에 위치하는 막대 그래프를 먼저 그린 뒤 위에 위치할 막대 그래프를 그릴 때 .bar() 메서드에 bottom 키워드를 제공함으로써 구현할 수 있습니다. bottom 키워드의 값은 아래에 위치하는 데이터의 y-value 입니다.
book_hours = [2, 3, 4, 2, 1]
video_game_hours = [1, 2, 2, 1, 2]
# 아래에 위치하는 막대 그래프를 먼저 그립니다
plt.bar(range(len(video_game_hours)), video_game_hours)
# 위에 위치하는 막대 그래프를 그릴 때 bottom 옵션을 설정합니다
plt.bar(range(len(book_hours)), book_hours, bottom=video_game_hours)
Error Bars
막대 그래프를 그릴 때 막대의 높이 값이 불확실할 때가 있을 수 있습니다. 예를 들면 다음과 같은 경우가 있을 수 있습니다.
- 한 학년의 각 학급 학생 수의 평균은 30명 이지만 학급에 따라 학생 수가 18명인 반도 있고 35명인 반도 있는 경우
- 특정 과일의 측정된 무게가 35g 이지만 과일에 따라서 30g일 수도 있고 40g 일 수도 있는 경우
이러한 불확실성을 그래프에 나타내는 방법은 막대 그래프에 error bars를 그리는 것입니다. Error bars가 포함된 막대 그래프는 다음괕이 그릴 수 있습니다.
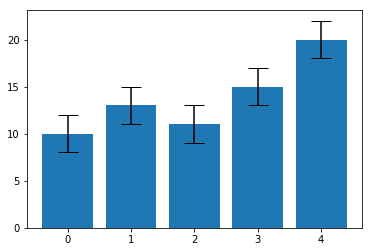
검은색 실선으로 그려진 부분이 바로 error bar입니다. 검은색 실선이 세로로 길 수록 더 많은 불확실성을 가진다는 의미이며 양 끝의 가로선은 caps 로 error bars의 가독성을 높이는 역할을 합니다.
만약 +/- 2의 불확실성을 가지는 그래프를 나타내고자 한다면, .bar() 함수에 yerr 옵션을 2 로 설정하면 됩니다. 또한 caps을 잘 보이게 하기 위해서 capsize=10 옵션을 설정할 수 있습니다.
values = [10, 13, 11, 15, 20]
yerr = 2
plt.bar(range(len(values)), values, yerr=yerr, capsize=10)
또한 각 막대에 서로 다른 yerr 를 부여할 수 도 있습니다.
values = [10, 13, 11, 15, 20]
yerr = [1, 3, 0.5, 2, 4]
plt.bar(range(len(values)), values, yerr=yerr, capsize=10)
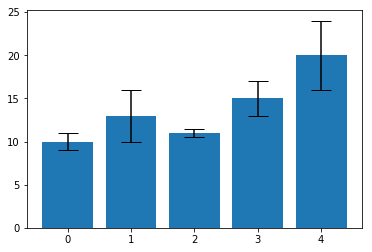
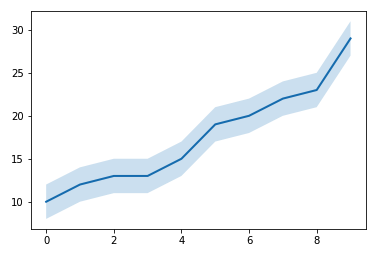
Fill Between
Matplotlib에서는 막대 그래프 뿐만 아니라 선 그래프에서도 불확실성을 나타낼 수 있는 plt.fill_between() 메서드를 제공하고 있습니다. 이 메서드는 다음 세 파라미터를 인자로 받습니다.
x-values-plt.plot()과 동일한 x 축 값들입니다lower bound for y-values- y 축 값의 error의 하한입니다upper bound for y-values- y 축 값의 error의 상한입니다
일반적으로 fill_between 은 alpha 값을 설정하여 그림자로서 에러를 나타낼 때 사용됩니다. 다음 코드는 +/- 2의 error를 갖는 데이터를 선 그래프로 나타냅니다.
x_values = range(10)
y_values = [10, 12, 13, 13, 15, 19, 20, 22, 23, 29]
y_lower = [ y_i - 2 for y_i in y_values ]
y_upper = [ y_i + 2 for y_i in y_values ]
plt.fill_between(x_values, y_lower, y_upper, alpha=0.2) # 음영 처리된 에러를 그립니다
plt.plot(x_values, y_values) # 실선을 그립니다
plt.show()
Pie Chart
만약 각각의 데이터가 전체 데이터 중 차지하는 비율을 나타내고자 한다면 pie chart(원 그래프)가 유용하게 사용될 수 있습니다. Pie chart는 다음과 같은 데이터를 시각화 할 경우에 사용될 수 있습니다.
- 오늘 먹은 점심 식사에 포함된 탄수화물, 단백질, 지방의 비율
- 대통령 선거에서 각 후보별 지지율
Matplotlib에서는 원 그래프를 그릴 수 있도록 plt.pie() 메서드를 제공합니다. 파라미터로는 그저 시각화할 데이터를 전달해 주면 됩니다.
budget_data = [500, 1000, 750, 300, 100]
plt.pie(budget_data)
plt.show()
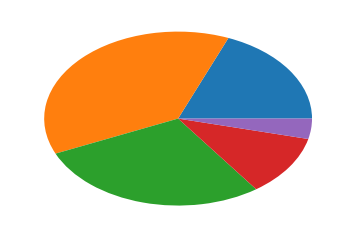
그런데 위 원 그래프는 찌그러져서 보기에 좋지 않습니다. 이런 문제로 인해 Matplotlib로 원 그래프를 그릴때, 거의 항상 axes를 동등하게 설정해 주어야 합니다. 즉, plt.axis('equal') 를 호출하면 다음과 같이 예쁘게 원 그래프가 그려집니다.
또한 이대로는 위 데이터가 의미하는 바가 무엇인지 이해하기 어렵습니다. 각 데이터가 의미하는 바가 무엇인지 나타내기 위해 다음과 같은 방법을 활용할 수 있습니다.
- legend를 달아서 각 label 표시해주기
- 각 데이터가 존재하는 영역에 label 표시해주기
두 가지 방법을 한번 구현해 봅시다.
Method 1
아래 코드는 각 카테고리의 이름을 legend로 표시해 줍니다.
budget_data = [500, 1000, 750, 300, 100]
budget_categories = ['marketing', 'payroll', 'engineering', 'design', 'misc']
plt.pie(budget_data)
plt.legend(budget_categories)
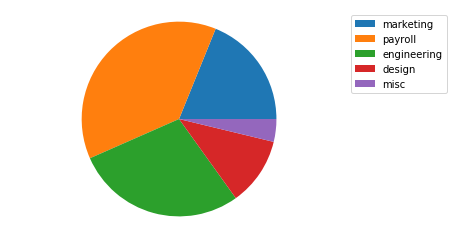
Method 2
아래 코드는 원 그래프에서 각 데이터가 존재하는 영역에 각 카테고리의 이름을 label로 표시해줍니다.
plt.pie(budget_data, labels=budget_categories)
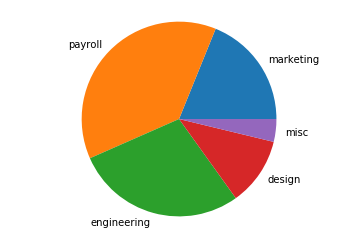
원 그래프에 적용할 수 있는 또 다른 유용한 라벨링 방법은 바로 각 데이터가 차지하는 비율을 나타내는 것입니다.
Matplotlib는 .pie() 메서드에 autopct 라는 옵션을 제공하면 자동으로 각 비율을 계산해서 format에 맞게 표현해줍니다. 이 때 autopct 옵션의 값으로 string formatting 을 적용한 스트링 값을 전달하여 각 비율이 어떻게 보일지를 설정해줘야 합니다. 각 데이터가 차지하는 비율을 소수점 1자리까지 나타내는 코드는 다음과 같습니다.
plt.pie(budget_data, labels=budget_categories, autopct='%0.1f%%')
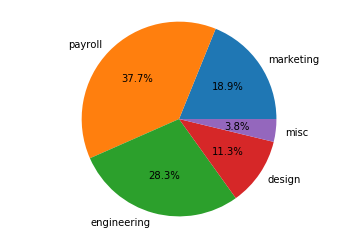
Histogram
때로는 데이터에서 많은 직관을 얻기 위해 모든 값들을 시각화 하고싶을 수 있습니다. 이 때 활용할 수 있는 것이 바로 histogram(히스토그램) 입니다.
Histogram은 특정 영역에 얼마나 많은 데이터가 분포하고 있는지를 나타냅니다. 이러한 특정 영역은 bin이라고 불리며, 한 히스토그램에서 모든 bin은 동일한 크기(width)를 갖습니다. 각 bin은 해당 bin에 속하는 값들의 수를 나타냅니다. 아래 그림은 히스토그램의 한 예시입니다.
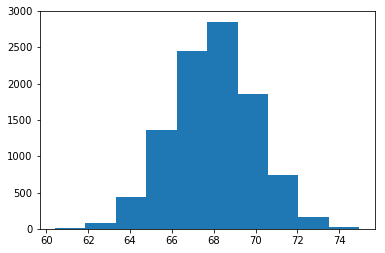
Matplotlib에서 히스토그램을 그리려면 plt.hist() 메서드를 활용하면 됩니다. plt.hist() 메서드는 주어진 데이터셋에서 최소값과 최대값을 찾아서 10개의 동일한 width를 갖는 bin을 생성합니다. 위 히스토그램은 다음 코드로 생성할 수 있습니다.
plt.hist(dataset)
plt.show()
만약 bin의 수를 조정하고자 한다면 .hist() 함수의 bins 옵션을 원하는 숫자로 설정하면 됩니다. 또한 range 옵션을 설정하여 보여주고자 하는 영역을 지정할 수 있습니다. 예를 들어, 범위가 66부터 69까지고 40개의 bins로 나누어지는 히스토그램은 다음과 같이 생성할 수 있습니다.
plt.hist(dataset, range=(66,69), bins=40)
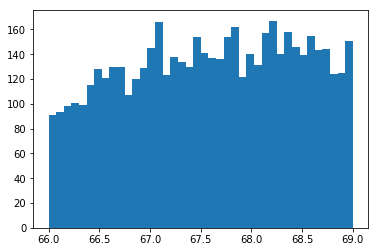
히스토그램은 데이터가 어떻게 생겼는지 확인할 수 있는 가장 강력한 방법 중 하나입니다. 히스토그램을 그리면 데이터가 어떤 분포를 따르는지, 한쪽으로 치우치진 않았는지 등의 정보를 확인할 수 있습니다. 이러한 직관을 얻음으로써 다음에 필요한 분석 과정은 무엇인지 발견할 수 있습니다.
Multiple Histogram
두 데이터의 분포를 비교하고 싶을 경우, 하나의 plot에 여러 히스토그램을 나타낼 수 있습니다. 예를 들어, 남자와 여자의 키 분포를 비교하고 싶다고 생각해봅시다. 그런데 두 히스토그램이 겹치는 부분은 한 분포가 다른 분포에 의해 가려지기 때문에 확인할 수 없게 됩니다.
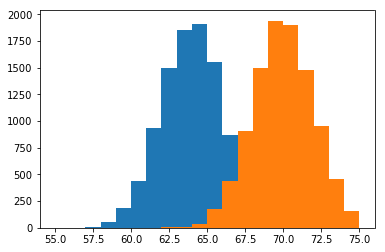
위와 같은 문제를 해결하기 위해 다음과 같은 몇 가지 해결책을 적용할 수 있습니다.
히스토그램에
alpha값을 적용하여 투명하게 만듭니다.plt.hist(a, range=(55, 75), bins=20, alpha=0.5) plt.hist(b, range=(55, 75), bins=20, alpha=0.5)
.hist()메서드에histtype옵션으로'step'을 제공합니다. 이는 히스토그램을 계단식 그래프로 나타냅니다.plt.hist(a, range=(55, 75), bins=20, histtype='step') plt.hist(b, range=(55, 75), bins=20, histtype='step')
여러 히스토그램을 하나의 plot에 나타낼 때 맞딱뜨릴 수 있는 또 다른 문제는 바로 데이터의 수가 상이하게 차이가 나는 경우 다른 히스토그램의 분포가 상대적으로 작게 나타난다는 것입니다. 이는 시각적으로 두 분포를 비교하기 어렵게 만듭니다. 예를 들어 다음과 같은 히스토그램이 있다고 생각해봅시다.
a = normal(loc=64, scale=2, size=10000)
b = normal(loc=70, scale=2, size=100000)
plt.hist(a, range=(55, 75), bins=20)
plt.hist(b, range=(55, 75), bins=20)
plt.show()
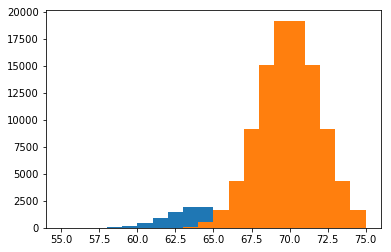
위 경우 주황색 히스토그램의 데이터 수가 파란색 히스토그램보다 10배 더 많기 때문에 크기가 상이하게 차이가 납니다. 이러한 문제를 해결하기 위해선 .hist() 함수를 호출할 때 normed=True 옵션을 설정해 주면 히스토그램의 전체 영역의 합이 1이 되도록 만들어 줍니다.
plt.hist(a, range=(55, 75), bins=20, alpha=0.5, normed=True)
plt.hist(b, range=(55, 75), bins=20, alpha=0.5, normed=True)
plt.show()
결과적으로 두 히스토그램의 분포를 눈으로 비교하기 쉽게 만들어 줍니다.
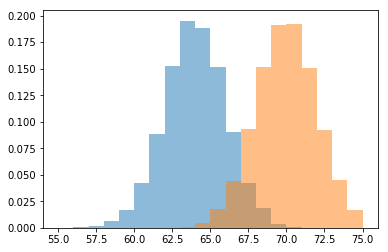
Review
지금까지 Matplotlib를 활용하여 데이터를 다양하게 시각화하는 방법에 대해서 알아보았습니다. 이번 포스팅에서 배운 내용을 정리하면 다음과 같습니다.
- How to compare categories of data with bar graphs
- Create side-by-side bar graphs
- Create stacked bar graphs for easier comparisons
- Add error bars to graphs
- Use
fill_betweento display shaded error on line graphs - Create and format pie charts to compare proportional datasets
- Analyze frequency data using histograms, including multiple histograms on the same plot
- Normalize histograms
이제 데이터를 시각화하는 여러 방법을 알게 되었으니, 다양한 데이터를 만나러 가봅시다😊